
每日經濟新聞
陳植
2025-01-27 09:48


DeepSeek,又一次在海外掀起巨浪。
自DeepSeek在1月20日發布新模型DeepSeek-R1并同步開源模型權重后,這家來自中國的AI創業公司引發了全球AI科技圈的關注。同時,最近包括紐約時報、經濟學人、華爾街日報等在內的多家英美主流媒體都報道了DeepSeek的研究進展,高度贊揚其模型的強大性能。其中,CNBC還發文稱:“DeepSeek-R1因其性能超越美國頂尖同類模型,且成本更低,算力消耗更少,引發了硅谷的恐慌”。
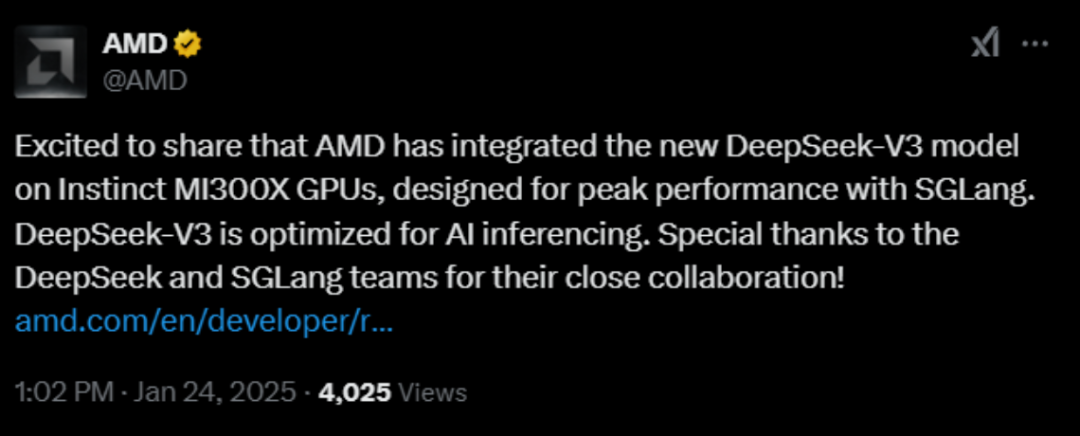
值得注意的是,英偉達的競爭對手、知名半導體公司超微半導體(AMD)昨日發布消息稱,已將DeepSeek-V3模型集成到AMD的芯片產品Instinct MI300X GPU上,該模型旨在與SGLang一起實現最佳性能。DeepSeek-V3針對Al推理進行了優化。業內人士分析稱,AMD作為全球領先的芯片廠商,通過與DeepSeek合作將為AI推理帶來新的想象空間,也有望動搖“英偉達+OpenAI”聯合主導的行業格局,改變既有的游戲規則。
在去年底DeepSeek-V3發布后,業內就掀起了關于DeepSeek打破算力需求“怪圈”的討論。在最近兩天DeepSeek-R1引發海外廣泛討論后,1月24日,英偉達股價又大跌3.12%。
值得一提的是,1月26日,有網友反映,DeepSeek崩了,提示服務器繁忙。14時56分,證券時報記者實測發現,已可以正常使用。

記者實測頁面
據媒體消息,DeepSeek回應稱,今天下午(1月26日)DeepSeek確實出現了局部服務波動,但問題在數分鐘內得到解決。此次事件可能與新模型發布后的訪問量激增有關,而官方狀態頁未將其標記為事故。
DeepSeek讓硅谷巨頭不淡定了
據DeepSeek介紹,其最新發布的模型DeepSeek-R1在后訓練階段大規模使用了強化學習技術,在僅有極少標注數據的情況下,極大提升了模型推理能力。在數學、代碼、自然語言推理等任務上,性能比肩OpenAI o1正式版。
這一模型發布后,引發了海外AI圈眾多科技大佬的討論。例如,英偉達高級研究科學家Jim Fan就在個人社交平臺上公開發表推文表示:“我們正身處這樣一個歷史時刻:一家非美國公司正在延續OpenAI最初的使命——通過真正開放的前沿研究賦能全人類。看似不合常理,但最有趣的結局往往最可能成真。”
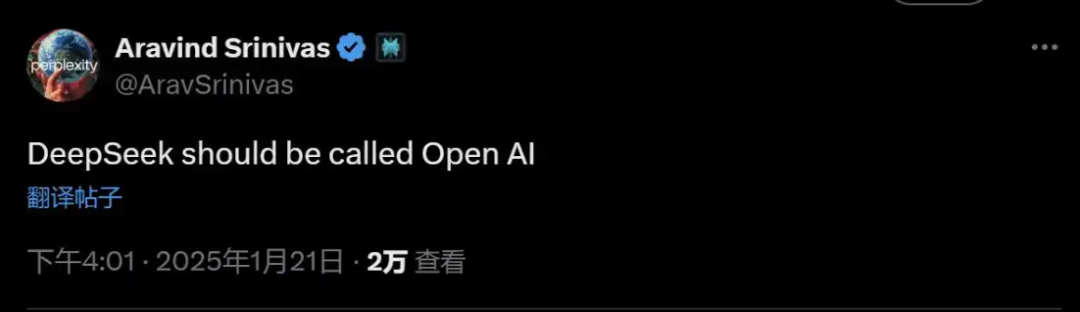
在近日舉辦的2025年達沃斯論壇上,AI初創公司Scale AI創始人Alexandr Wang公開評論DeepSeek的新模型,表示“DeepSeek 新模型的表現令人印象深刻,尤其是在模型推理效率方面。我們必須認真對待來自中國的這些發展”。他還表示,DeepSeek的AI大模型性能大致與美國最好的模型相當。另外一家知名AI創業公司、被稱為谷歌殺手的Perplexity首席執行官Aravind Srinivas甚至直接評論稱:“DeepSeek才配叫做OpenAI”。
DeepSeek這個AI黑馬,在去年底發布DeepSeek-V3時就吸引了硅谷的目光,并因其低調的作風被稱為“來自東方的神秘力量”。新模型發布后,硅谷巨頭陷入了既興奮又緊張的狀態。一則來自Meta員工在匿名社區Teamblind的爆料稱:“Meta的生成式人工智能團隊正陷入恐慌。”帖子進一步爆料說,目前Meta工程師們正在瘋狂拆解DeepSeek,試圖復制其中的一切。“我不是在夸張,事情就是這么緊迫”。
同時,由于DeepSeek擅長“小成本辦大事”,通過采用創新架構和優化算法實現具有更高經濟性的訓練效果和更高效的推理。DeepSeek-V3的總訓練成本僅為550萬美元左右,是Llama-3405B超6000萬美元訓練成本的十分之一不到。該爆料帖還稱,Meta管理層正面臨嚴峻的財務壓力,該生成式AI部門數十位高管,“每個人的年薪都超過了DeepSeek-V3的全部訓練費用。如何向公司高層解釋這種投入產出比,已成為他們的噩夢”。
不僅硅谷巨頭深受震動,英美多家主流媒體也聚焦DeepSeek展開了專門的報道。比如,英媒經濟學人指出,“目前訓練一個美國大語言模型要花費數千萬美元,而DeepSeek的支出不到600萬美元。這種廉價訓練正隨著模型設計的發展改變整個行業,這可能導致更多針對特定用途的專業模型涌現,打破贏家通吃的市場格局。”

金融時報也發布了題為“中國一家小小的AI創業公司如何讓硅谷感到震驚”的文章。文章中說道,“R1模型的發布在硅谷引發一場激烈辯論,主題是包括Meta和Anthropic在內資源更雄厚的美國人工智能企業能否守住技術優勢”“DeepSeek沒有從外部基金籌集資金,也沒有采取重大舉措將其模型商業化。DeepSeek的運作方式就像早期的DeepMind,專注于研究和工程”。
股民也焦慮:DeepSeek利空英偉達?
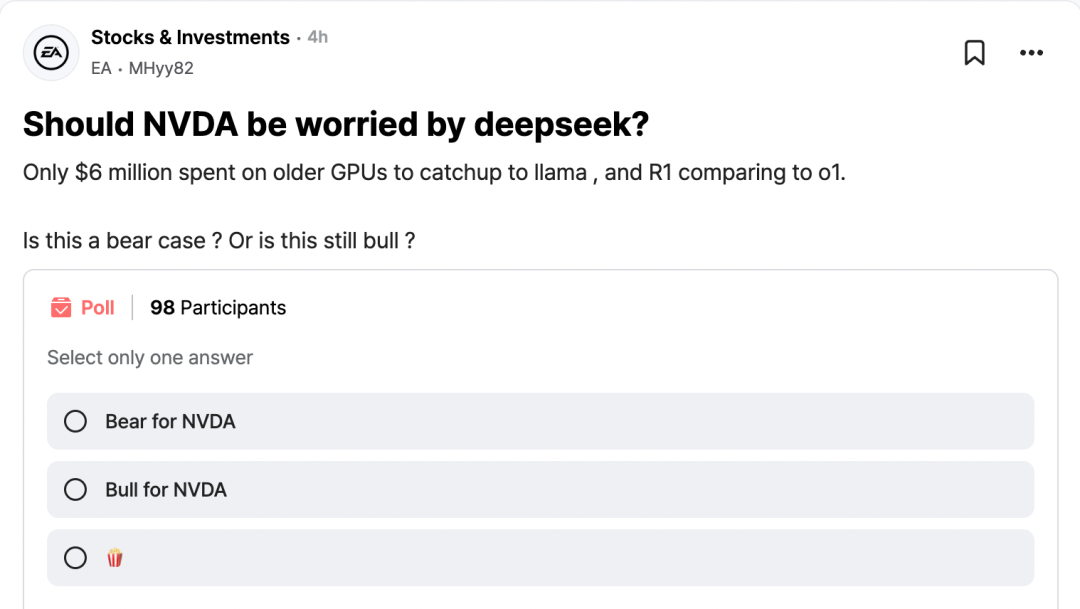
在Mera員工爆料的匿名社區Teamblind上,證券時報記者發現已有多個帖子在討論DeepSeek,除了模型成本與性能等方面的技術討論,還有股民發起了題為“英偉達是否應該為DeepSeek感到擔憂”的投票。帖子還給了一些“前情提要”,提示DeepSeek僅用不到600萬美元在性能沒那么強的GPU上訓出了V3模型,效果直逼Meta的開源模型Llama,而且最新發布的R1模型足以媲美OpenAI的o1模型。
事實上,自去年年底DeepSeek發布V3模型后,業界就關注到,DeepSeek的成功,背后的更大意義在于可以通過軟件優化,在有限的硬件資源下實現頂尖的模型性能,減少對高端GPU的依賴。有觀點認為,DeepSeek-V3極低的訓練成本預示著AI大模型對算力投入的需求將大幅下降,這無疑將利空全球AI算力的核心供應商英偉達。
據證券時報記者了解,大模型主要分為訓練和推理兩個階段,訓練是指用大量數據訓練大模型,通常需要極高的計算能力和存儲資源;推理是指將訓練好的模型應用于實際任務(如提問并生成文本、識別圖片與視頻等)。這二者采用的是不同的芯片,過去兩年各大廠商都在加緊訓練大模型,算力主要體現在訓練階段,而其中模型訓練是英偉達GPU的優勢所在。但隨著模型基本訓練成型及AI應用的爆發,算力的增長或將更側重于推理側。
同時,DeepSeek不僅將模型訓練成本大幅降低,而且發布的新模型R1也同步開源模型權重,公開了完整訓練細節,挑戰了閉源系統的優勢。隨著DeepSeek將AI大模型技術及使用門檻降低,有市場人士擔憂,DeepSeek R1的崛起可能會削弱市場對英偉達AI芯片需求的預期,對英偉達的市場地位和戰略布局產生影響。
不過也有觀點認為,DeepSeek只計算了預訓練的算力消耗,但數據配比、合成數據的生成和清洗等方面也需要消耗大量算力。同時,訓練成本的降低未必意味著算力需求下降,只代表模型廠商可以使用性價比更高的方式去做模型極限能力的探索。中信證券研報也指出,DeepSeek-V3意味著AI大模型的應用將逐步走向普惠,助力AI應用廣泛落地,同時訓練效率大幅提升亦將助力推理算力需求高增。






